当社が主導した論文が、世界最高峰のマシンラーニング(ML)学会「NeurIPS」に2年連続で採択されました。NeurIPS 2023では、日本からの投稿は3,000件以上にも上りますが、厳しい審査があり、採択はわずか100件程度でした。その中で、バイオ系スタートアップの採択は極めて異例です。COGNANOを支えてくださった取引先各社、助成元、投資家の皆様、共同研究パートナーのさくらインターネット様、温かく応援してくださっているサポーターの皆様に、心より御礼申し上げます。
今回の成果は、COGNANO独自の「抗原ラベル付き抗体ビッグデータ」を活用し、言語モデルの可能性を実証したものです。特に、ML&テックリードの鶴田、MLOps担当の田村をはじめ、小さなスタートアップの研究者たちが、バイオとITの境界を越えて協力し合った成果でもあります。
私たちのバイオデータセットと計算機科学のシナジーにより、初めて可能となったテーマが3つあります。
- 細胞レベル:「正常細胞と異常細胞」を見分ける
- 分子レベル:アミノ酸アルファベット配列の照合により、抗体と抗原のペアリングを予測する
- 原子レベル:目的立体構造に結合する抗体を選び出す
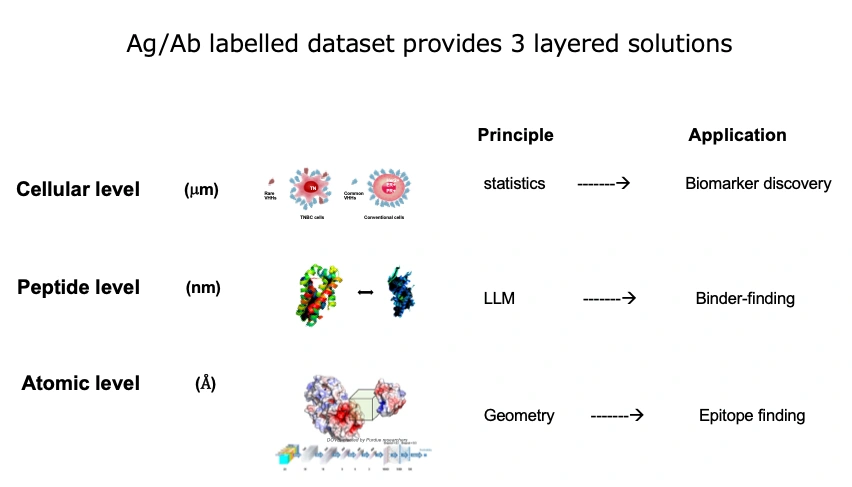
抗体データを用いるには高度な数学的手法と膨大な計算パワーが必要です。これまで、抗原と抗体がペアとなった大規模なデータセットはほとんど存在せず、どのようなデータ処理が必要なのか、前例が非常に少ない状況でした。COGNANOは世界で初めてビッグデータを自社で内製し、MLOps の技術を活用してデータをパッケージ化してクラウドに蓄積しました。この体制により、3つの課題に挑戦しています。今回NeurIPSで採択された論文は、テーマ2に該当します。ちなみに、テーマ1は難治がんの新標的分子の発見としてすでに成果を挙げています。今後はテーマ3をITテックと協力して開発していく予定です。テーマ3は立体構造の理解から始まるため、話題のAlphaFoldのようなアルゴリズムとの連携が課題となるでしょう。一般に、IT業界は抗原抗体データセットからテーマ3をイメージすることが多いようです。
活用例をいくつかご紹介しますと、以下のような流れになります。
- 未知のバイオマーカーを発見し、がん細胞の発見や治療に向けた早期診断や薬の開発を可能にする
- 変異するウイルスなどに迅速に対応し、ライブラリから予防薬を発見する
- 特殊な構造モチーフに結合する、従来の手法で作りにくかった薬を機械でデザインする
私たちは、10年以内に新薬は(部分的であれ)AIによって予測される時代が来ると考えています。今回採択された論文の詳細は、鶴田の解説ブログをご覧いただくとして、バイオ研究者の視点から、AI創薬がどのように進んでいくのかを予測してみたいと思います。
ここで参考になるのはChatGPTでしょう。どのようなモデルを構築するにせよ、マシンラーニング(ML)が成立するためには、膨大なデータが必要です。ChatGPTを成功に導いたAltmanチームのすごみは、「どれほどのデータを投入すれば、機械がまともに答えるようになるのか」誰にも保証できない状況を打ち破ったことにあります。OpenAIには膨大な計算リソースが必要だったはずで、資金との競争も熾烈だったに違いありません。
バイオ業界にとっての課題は、ChatGPTに投入されたような量のデータが存在するのか、という点です。答えはノーです。AlphaFoldはバイオ系MLの成功例として有名ですが、これは過去に登録された数十万のタンパク質立体構造データ、すなわち規則性が高く、文脈が明確な情報をトレーニングすることで構築されたアルゴリズムです。しかし、創薬において知りたいことは、タンパク質の立体構造だけではありません。薬は標的分子に結合して初めて機能を発揮するため、分子間相互作用の理論が重要になりますが、この分野のデータは圧倒的に不足しています。

抗体の抗原への結合はバイオ実験を経てゼロイチ(バイナリー)で表示されることから、明確なラベルデータとなります。私たちの論文で、COGNANOのコンセプトが2年連続で実証されました。AI創薬に必要な3.の技術でも、良質なデータが有効に働くと考えています。トレーニング用データセットのクオリティがMLの学習効率に与える影響は、多くの研究で実証されています。これらの研究事例については、鶴田のエッセイをご覧ください。

COGNANOというより、アルパカが産出する良質なラベルデータは、AI創薬競争の勝敗を分ける鍵となり得ます。IT業界でも、COGNANOのデータに注目し、共同研究を希望するチームが増えています。また、今年6月にロンドンテックウィーク(LTW)でピッチさせていただいた際、反響をいただき、その後、英国から複数のチームに訪問いただきました。MLエンジニアにとって、COGNANOが進めているAI創薬の方向性は理解しやすいのです。一方、バイオ業界でも「面白いことをやっている」と関心いただくことが増えています。今後も論文発表と出願を通じて、COGNANOの成果をお知らせしていく予定です。
私自身は、新技術から生まれるデータで「MLを加速する!」と意気込んでいます。これまでのバイオ研究は、「極上のデータ」だけを論文化し、99.99%のデータは埋もれてしまっていました。しかし、MLへのデータ提供により、今では捨てる部分がなく全て活用できることに感謝しています。この変化は、重大な産業構造変化も示唆しています。バイオの基礎研究がアカデミアでしか成り立たなかった原因は、経済効率の悪さにあったと言えます。産業から見れば、効率の悪い基礎研究は大学に任せ、利益に直結する部分を担当するのは当然のことです。ところが、バイオ基礎研究がデータサイエンスに変わったら、ビジネスとしても成立する可能性が出てくるのです。これは、今まで意味を持たなかったデータの活用が成果を左右する時代になることも意味します。昔、厄介な液体でしかなかった原油が、内燃機関の発明により突然富に変わったように。こう考えると、まさしくAlphaFoldが注目されている現象も、産業構造的な理由であると理解できます。問題は、どのようなバイオデータを生産し、どのチームが参加すれば、人類史上初めてのAI創薬レースに勝てるのか、に絞られてきました。今後のCOGNANOの活躍にご注目ください!